Navigating in EU Vocabularies website
Accessing the datasets on the website and their contents requires a number of features and functionalities to help the user find faster and easier the elements of his interest. We have defined a navigational architecture based on a number of “views” that try to standardise the presentation of the data to make it easier to understand. The sections bellow present the description of each view and their contents.
To make them easily reachable, the datasets available on the website have been grouped based on their classification (see Controlled Vocabularies and Models menus) and usage scenario (see Business collections menu). Each of the dataset classes includes a number of entries that can vary from several to several hundreds. Finding what you are looking for in those lists happens accessing the so called Asset list view.
Once you have found the dataset in the Asset list view you can chose to view the dataset metadata and its dependencies (Dataset view) or to browse the content of the dataset (Concept scheme view)
Asset list view
The asset list is a summary of all the datasets grouped under a single category (e.g. Taxonomy, Alignments, etc.).
In large asset lists (like Authority tables) you can easily filter the assets using the “Filter by:” function

Accessing the dataset or its concept scheme is now possible directly from the asset list.
On the left side of each dataset name you can see two icons each providing a direct link to the respective view.
Content related views
The various content related views are following a common interface design scheme based on a set of informational areas.
Wherever possible we have tried to preserve a similar structure of the information displayed in each view. The commonalities and differences are listed below.
Common informational areas
Each of the view presents several informational areas and navigational features as following:
- Top left side of the view – Provides information about the level where the user is in (the options being Dataset, Concept or Concept scheme) as well as the name, version and URI of the respective entity viewed. Depending on the context, the type of the dataset is also displayed there (if applicable).
- Top right side - Offers a set of blue buttons that are changing depending on the context offering either the ability to go back to the Asset list or switch from Dataset view to Concept scheme view (or vice versa)
- Central part of the view - Contains the main informational area. Depending on the context where you are here you will see the description of the dataset or different levels and renderings of its content
We have preserved the same architecture across the various view as described in the sections bellow.
Dataset view
The dataset view represents the main access point for accessing the metadata and all the dependencies of a dataset.
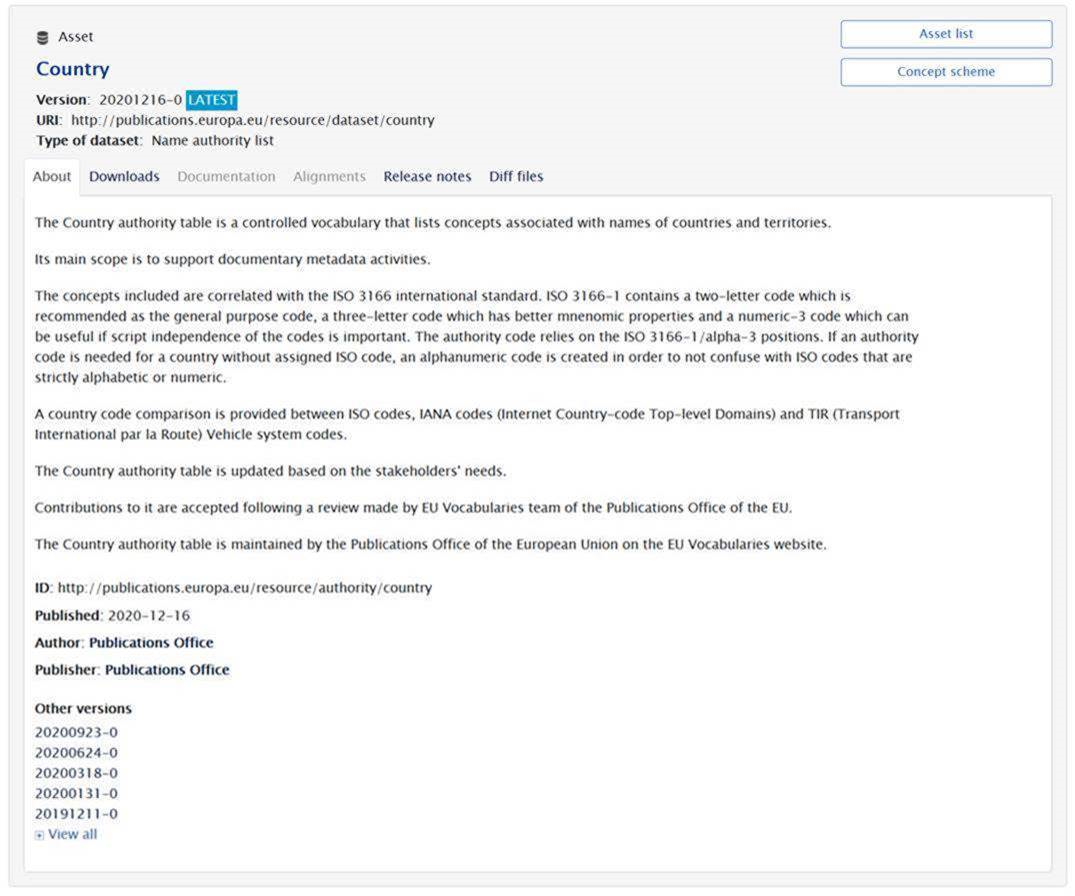
The dataset view has a number of particularities as following:
- The dataset version is usually accompanied by a blue icon containing the word LATEST, indicating that the version shown is the last one available. To access previous versions of the dataset, you can either look in the About section of the view in the Other versions area (at the base of the view), or in the Releases menu
- For Controlled Vocabularies, to keep the user well informed, the Type of dataset is displayed in the header of the view. The types used are following internationally recognised standard Knowledge Organisation Systems that are described in our Asset classification dataset.
Several tabs are available here, each of them becoming active or not depending on the available dependencies. Those tabs are:
- About – Contains the main metadata fields of the dataset as following:
- Dataset description
- ID – Unique identifier
- Published - Date of publication of the dataset
- Author – The institution (or person) where the dataset was originated and also the copyright owner of the dataset.
- Publisher – Given the scope of the website, the publisher is always the Publication Office
- Other versions – Provides a list with all available version of the dataset. Usually the versions are identified with the date of publication and release number during that year (a dataset can be published multiple times over a year)
- Downloads – Provides a list of available versions of the dataset in different formats or for more complex datasets (e.g. models) the different components of their architecture (schemas, entity files, etc.). For the main reference dataset types like thesauri, taxonomies and authority tables, the formats provided are:
- SKOS – The base RDF version of the dataset with the core set of elements. This is the version of the dataset that it should be used in most cases.
- SKOS-AP-ACT – The complete RDF version of the dataset containing complementary data including editorial info (e.g. dates when a concept was submitted, accepted and created), SKOS-XL notations of the labels, etc. This is a version that can be useful for reference purposes in cases where the full set of information about the concepts are needed.
- XML – An XML structured version of the information found also in the SKOS core version
- GC – The Genericode representation of the dataset following the standard representation used for code lists
- Documentation – Gives access to the documents describing the content and structure of the dataset
- Alignments – If applicable for the type of dataset, here the user will find files presenting the correspondence (exactMatch, closeMatch) of the concepts inside the dataset with concepts in other public reference datasets that can be relevant for the user. This section is supporting our effort targeting the linking of all available data within the larger Linked Open Data environment
- Release notes – Lists the release notes of published versions of the dataset. Each release note describes the changes applied to the dataset for the new version.
- Diff files – Provides the result of a diff process between two consecutive versions of the dataset
Concept scheme view
The concept scheme view is the main content browsing area of the website. This view applies to all semantic datasets that are following the SKOS architecture and provides the user with the ability to see the content of the dataset (concepts and micro-thesauri).
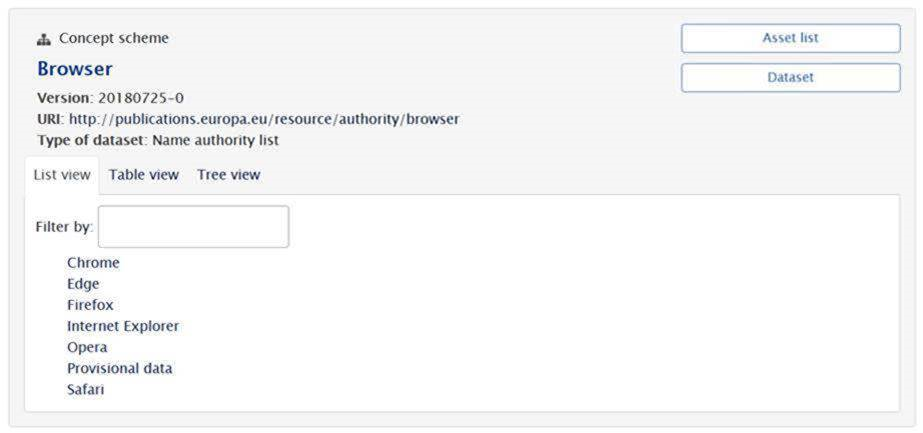
Other than the metadata and the navigational function described here, the view presents the user with 3 specific browsing views namely:
- Table view – A highly structured presentation of the dataset in a table mode that allow for quick view of the included concepts and a copy/paste of the concepts in other applications
- List view – A simple list of the concepts found inside the concept scheme
- Tree view – Provides (were applicable) a hierarchical view that allows the user to see the full architecture of the dataset
Concept view
The display structure of this view has a series of particularities that can mostly be associated with the origin of the concept in case. Two concept cases have been considered as following:
Generic concepts
The generic concept view is applicable to most concepts and can have a simple or more complex presentation depending on the complexity of the concept itself.

For simple concepts, the view will present just several basic properties (e.g. the label, alternate labels, identifier, last modification) while more complex concept can have tens of properties (e.g. https://op.europa.eu/en/web/eu-vocabularies/concept/-/resource?uri=http://publications.europa.eu/resource/authority/country/CZE) that can be grouped in different categories as following:
Valid since
Date when the concept became active an valid (e.g. 1993-01-01)
Identifier
Unique code associated with the concept (e.g. CZE, c_749f2ce9) given in order to support a proper referencing system
Labels
- PREFERRED - The main label associated with the concept (e.g. Czechia). A concept has one single preferred label for each language.
- LONG, ADJECTIVAL - Wherever necessary, different forms and linguistic representations of the concept can be associated with it as a complement to the preferred label (e.g. Czech Republic)
Language equivalents
Lists the preferred labels in each of the languages the concept is translated in.
Identifiers
Section listing different codes associated with the same concept in other public standards and references.
Other properties
Section listing properties that are mostly dependent on the specific context of the concept (e.g. language spoken in the country, currency used in the country)
History
Section presenting the evolution of the concept in time (records that have represented the same concept in the past as for example Predecessor: Czechoslovakia)
Mapping
List different links (with their Unique Resource Identifiers) between the concept and equivalent concepts in other public references (e.g. taxonomies, code lists, thesauries). Such links can be identified as closeMatch or exactMatch defining the level or equivalence between the two concepts.
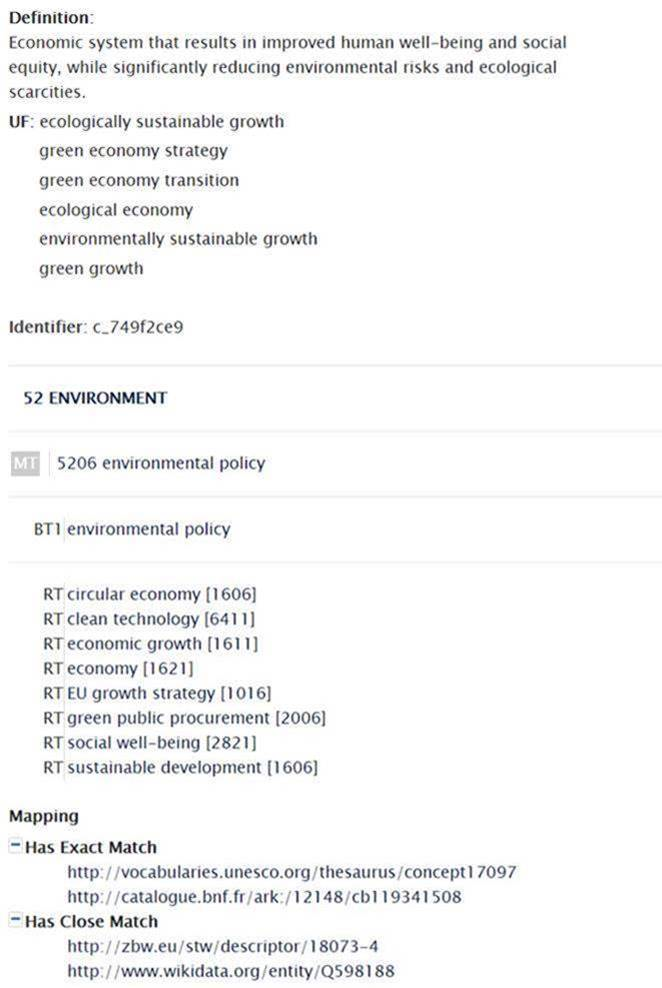
Thesaurus concept
Heavily hierarchical datasets (like some thesauries) include in their descriptions other properties like relations between concepts. Such relations are identified with the following strings that are used to prefix the respective links:
- MT – Identifies the parent of the described concept
- UF [Used form] – Equivalent or alternate label of the concept in the same language
- RT [Related concept] – Concepts having a meaning that can be considered as associated with the one described
- NT [Narrower concepts] - Concepts that describe a subset or a specific area in of the base concept. Narrow relations can build links on multiple levels identified with NT1, NT2, NT3.
- BT [Broader concepts] – Concepts with a more generic meaning covering subject that are encompassing the the concept described. Broader relation can build links on multiple levels identified with BT1, BT2, BT3.